

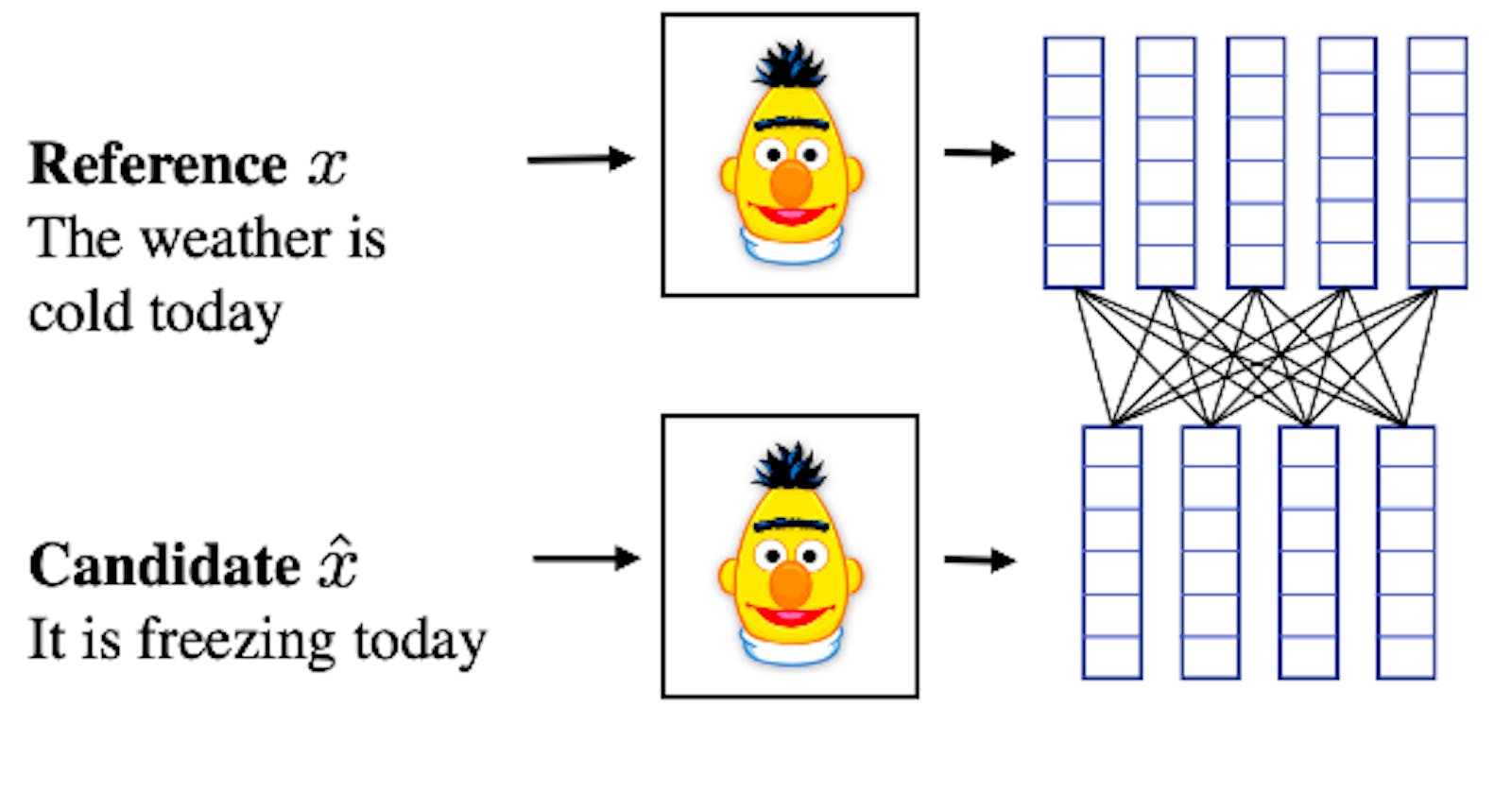
Introduction: Text similarity analysis plays a crucial role in the healthcare domain, enabling tasks like medical record matching, disease classification, and clinical document similarity assessment. In this tutorial, we'll delve into using BERT in Python to calculate text similarity, focusing on healthcare-specific applications and real-world examples.
Prerequisites: Ensure you have Python installed (version 3.6 or higher) and the necessary libraries:
Transformers library (for BERT)
Sentence Transformers library (optional, for alternative approaches)
SciPy library for cosine similarity calculation
You can install these libraries using pip:
bashCopy codepip install transformers sentence-transformers scipy
Step 1: Import Libraries Let's start by importing the required libraries for text similarity calculation:
pythonCopy codefrom transformers import BertTokenizer, BertModel
from sentence_transformers import SentenceTransformer
from scipy.spatial.distance import cosine
Step 2: Load BERT Model Load a pre-trained BERT model for text encoding:
pythonCopy codebert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased')
Step 3: Tokenize and Encode Texts Define two sample medical records or clinical notes and encode them using BERT:
pythonCopy coderecord1 = "Patient presents with symptoms of fever and cough, suggestive of respiratory infection."
record2 = "Subject exhibits signs of pneumonia, including fever, chest pain, and shortness of breath."
tokens1 = bert_tokenizer.encode(record1, add_special_tokens=True, return_tensors='pt')
tokens2 = bert_tokenizer.encode(record2, add_special_tokens=True, return_tensors='pt')
with torch.no_grad():
embeddings1 = bert_model(tokens1)[0][:, 0, :].numpy()
embeddings2 = bert_model(tokens2)[0][:, 0, :].numpy()
Step 4: Calculate Similarity Index Utilize cosine similarity to calculate the similarity index between the encoded embeddings of the medical records:
pythonCopy codesimilarity_score = 1 - cosine(embeddings1, embeddings2)
print(f"Similarity Index: {similarity_score}")
Real-World Example in Healthcare: Consider a scenario where healthcare providers need to compare patient symptoms or clinical notes for disease diagnosis or treatment planning. By using BERT-based text similarity analysis, healthcare professionals can quickly assess the similarity between medical records, prioritize patient care, and identify patterns or trends in symptoms across multiple cases. This approach enhances clinical decision-making, reduces manual effort, and improves patient outcomes.
Conclusion: BERT-based text similarity analysis is invaluable in the healthcare domain, offering efficient and accurate comparisons of medical records, clinical notes, or patient symptoms. By following this tutorial and incorporating BERT into healthcare applications, practitioners can streamline data analysis, enhance medical decision support systems, and deliver better patient care. Experiment with different medical text inputs and fine-tune models as needed to address specific healthcare use cases and improve overall healthcare delivery.